How to calculate evaluation loss correctly (HF Trainer is not correct!)

It is common to use cross entropy loss to evaluate LLMs’ performance, especially for text generation models. However, the loss calculation is somewhat not very standardized and even popular frameworks like Hugging Face may not give you the correct evaluation loss if you’re using their default settings.
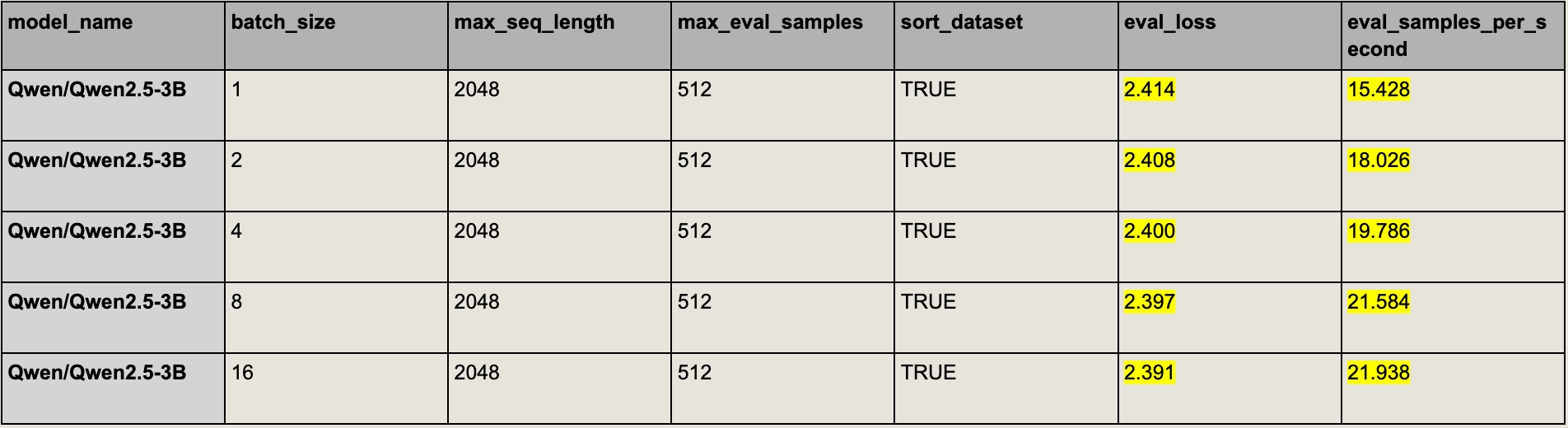
Last week I was using the Hugging Face Trainer to evaluate LLMs, and I noticed that eval loss consistently decreases as I increase the batch size:
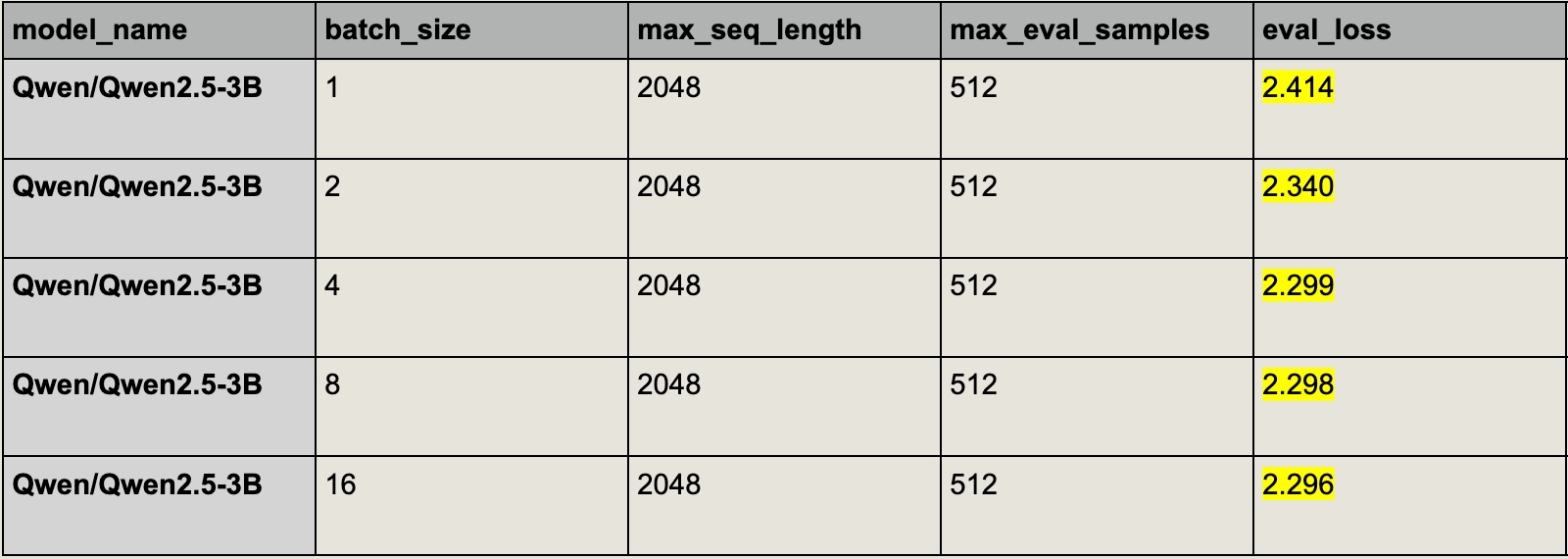
The full code is in the Appendix
But this should not be the case! Since we’re using the same set of data, we expect to always get the same evaluation result.
Macro-averaging Loss and Micro-averaging Loss
Before digging in, we will briefly introduce the two ways to calculate loss for causal LMs.
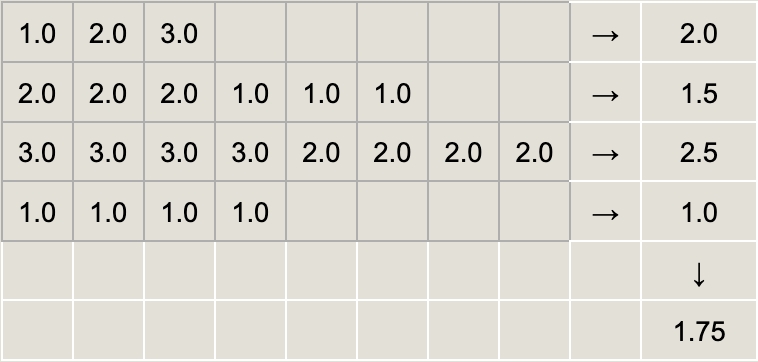
Macro-averaging:
Average on each sample first (excluding padding tokens), then average across all samples.
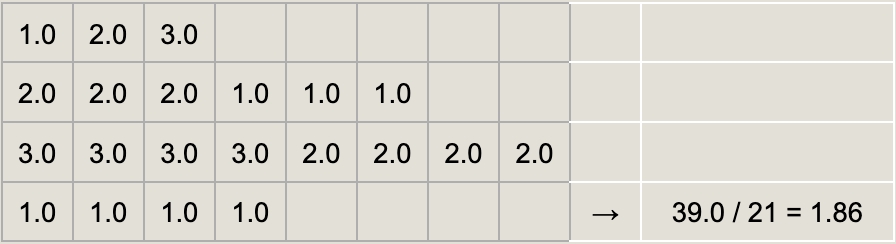
Micro-averaging:
Average across all tokens (excluding padding tokens).
I didn’t see much discussion on which average method we should use, but the two methods should be independent of the batch size.
HF Implementation Issues and Fixes
Let’s take a look at fixed_cross_entropy (in transformers/src/transformers/loss/loss_utils.py). It does a token-level sum then divides by the total non-padding token count (micro-averaging):

The problem is that they calculate the micro-averaging loss for each batch then simply average the loss across batches. However, each batch may contain a different number of tokens, so that the average of the average no longer equals the average of all.
If you want to get the correct loss, here are some ways to workaround it:
Set batch_size to 1 (only for macro-averaging loss).
When batch size is 1, the micro-averaging loss of each batch is simply the average loss of each sequence. Some might be concerned about the efficiency, but sometimes smaller batch sizes might actually run faster if the sequence length varies inside each batch (the more padding tokens, the more you waste!). For example, in our experiments, setting batch size to 1 not only gave the correct macro-averaging loss, but also ran fastest.
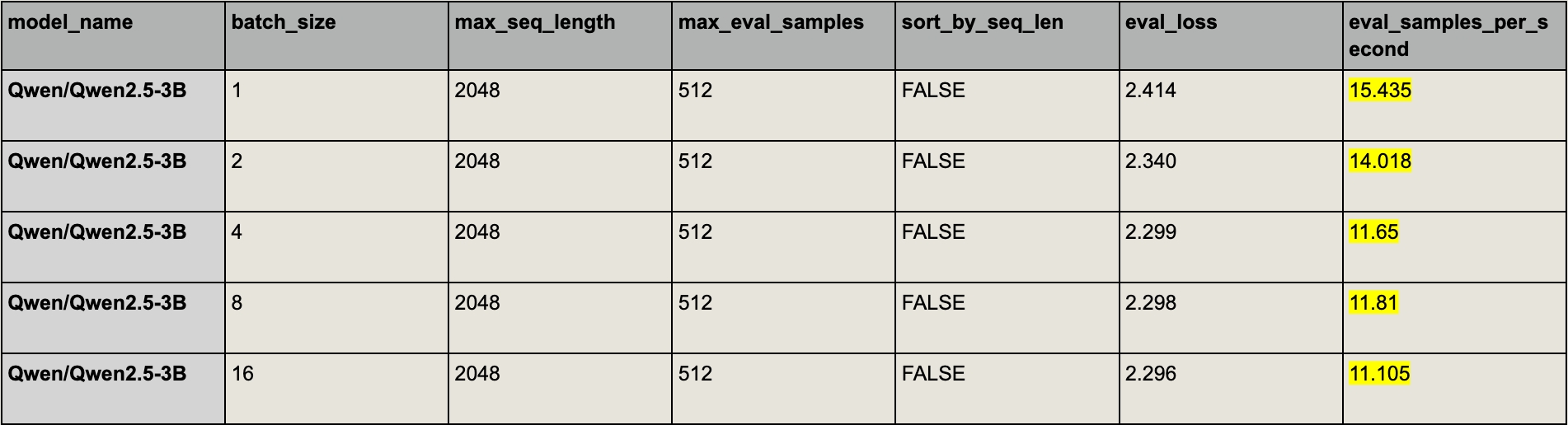
Sort the evaluation dataset by sequence length (making each batch have a similar length) (only for macro-averaging loss).
By sorting the evaluation dataset (you might not want to do it when training!), we ensure that each batch has a similar length, making the micro-averaging loss closer to the macro-averaging loss of the batch. As you can see, the impact on eval loss error is significantly less compared to the random ordering.
Another benefit of sorting is that it speeds up the evaluation process by reducing padding tokens.
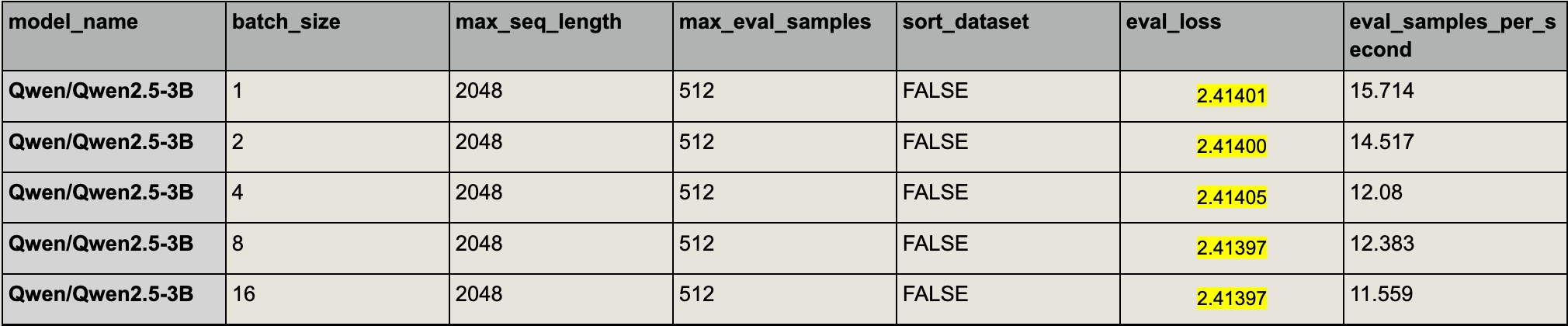
Write your own compute_loss function (recommended).
This is the ultimate solution, and the only way you can get micro-averaging loss right! Here’s my implementation for macro-averaging loss. The only limitation is that it requires the number of samples to be divisible by the batch size (you can add some context control to solve this limitation, we ignored this part for simplicity).

With correct implementations, eval loss is identical across batch sizes and input orderings, enabling a few nice benefits:
- 1. We can choose optimal batch size to speed up evaluation, especially when comparing models of different sizes.
- 2. Sorting samples by length before batching reduces padding, reducing evaluation time by over 50%.
Speed decreases with larger batch sizes (random batching).

Speed increases with large batches while keeping the loss identical (optimized batching).
We wanted to make people aware of this discrepancy and how to fix it. Enjoy!
Open Questions
- During training (not evaluation), which loss scheme is better (macro v.s. micro)?
(Appendix) Full Code

The implementation above always yields the same evaluation loss (as long as number of eval samples is divisible by the batch size).
(Appendix) HF Trainer Default Settings
